Apache Kafka Overview
- 10 minsIntroduction to Apache Kafka
Apache Kafka is a distributed platform designed for real-time data streaming. It enables applications to create, process, and analyze data streams in real time. Unlike traditional batch processing, where data is accumulated and then processed, Kafka continuously listens for new data and processes it as soon as it arrives. This makes it an essential tool for real-time analytics, event-driven architectures, and large-scale data integration.
How Kafka Works
Kafka is built on a Pub/Sub messaging system architecture, functioning as an enterprise messaging system. It consists of three main components:
- Producer – Sends data records (messages) to Kafka.
- Broker – Acts as a message broker, receiving and storing messages.
- Consumer – Reads and processes messages from the broker.
Kafka’s architecture allows producers to send data streams, brokers to store and manage them, and consumers to process them in real-time.
Kafka’s Origins and Evolution
Kafka was originally developed at LinkedIn to address data integration challenges. As organizations grew, so did the complexity of managing multiple backend applications, each generating and needing access to data. Traditional point-to-point integrations led to system failures and maintenance nightmares.
To solve this, LinkedIn introduced a broker-based Pub/Sub messaging architecture, where applications acted as producers and consumers. This streamlined data sharing and significantly improved system reliability.
Over time, Kafka evolved beyond a simple messaging system into a full-fledged streaming platform. It now includes additional components:
- Kafka Connect – Handles data integration across systems.
- Kafka Streams – Enables real-time stream processing.
- KSQL – Provides a SQL-like interface for querying streaming data.
Kafka Solution Patterns - When to Use What?
Kafka provides various patterns for different use cases.
1. Data Integration
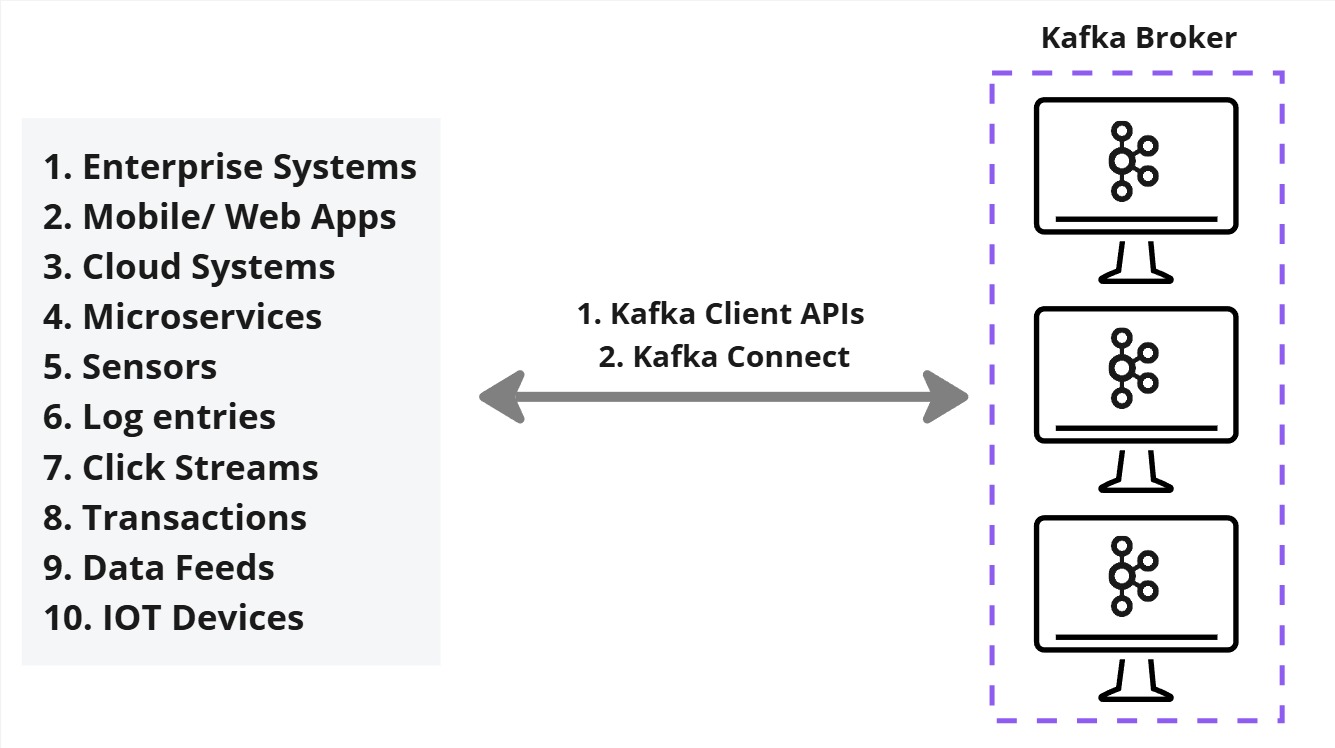
When dealing with multiple independent systems that generate, store, and own data, Kafka acts as a central hub to send and share specific parts of the data. This can be achieved using the Kafka Broker as the core message broker handling data distribution, Kafka Client API to create direct producer/consumer interactions or Kafka Connect for integrating external systems.
- Services that share data send it to Kafka Brokers.
- Consumers interested in the data retrieve it from Kafka Brokers.
Advantages:
- Decoupling of producers from consumers.
- Reliability and fault tolerance.
- Horizontal scalability.
- Performance benefits for time-sensitive data.
- Extensibility for different systems.
Choosing Between Kafka Client APIs and Kafka Connect
- Bespoke (custom-built) systems: Use Kafka Client APIs for direct control.
- COTS (Commercial Off-The-Shelf) products: Use Kafka Connect when possible.
- If no Kafka Connect connector exists for a COTS product: Develop a custom connector rather than using raw producer/consumer APIs.
2. Real-Time Stream Processing in Microservice Architecture
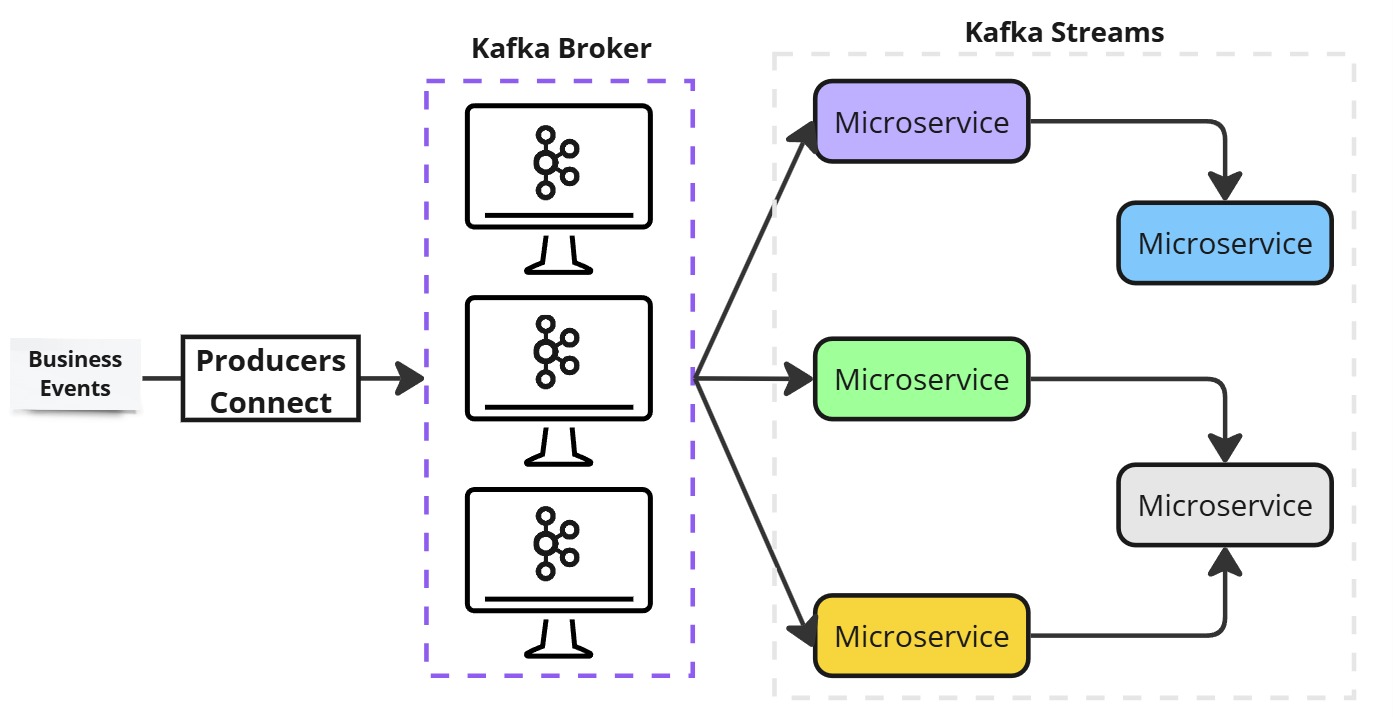
For real-time stream processing applications using a microservice architecture, leverage:
- Kafka Broker: Provides a backbone infrastructure, making data available to microservices.
- Kafka Client APIs (Producers only): Used to generate data streams.
- Kafka Streams: Handles business logic and stream processing efficiently.
Why Kafka Streams?
- Regular Kafka consumers lack advanced stream processing features.
- Kafka Streams provides better efficiency and scalability.
- If using COTS applications, prefer Kafka Connect over custom solutions.
Real-Time Stream Processing in Data Warehouses and Data Lakes
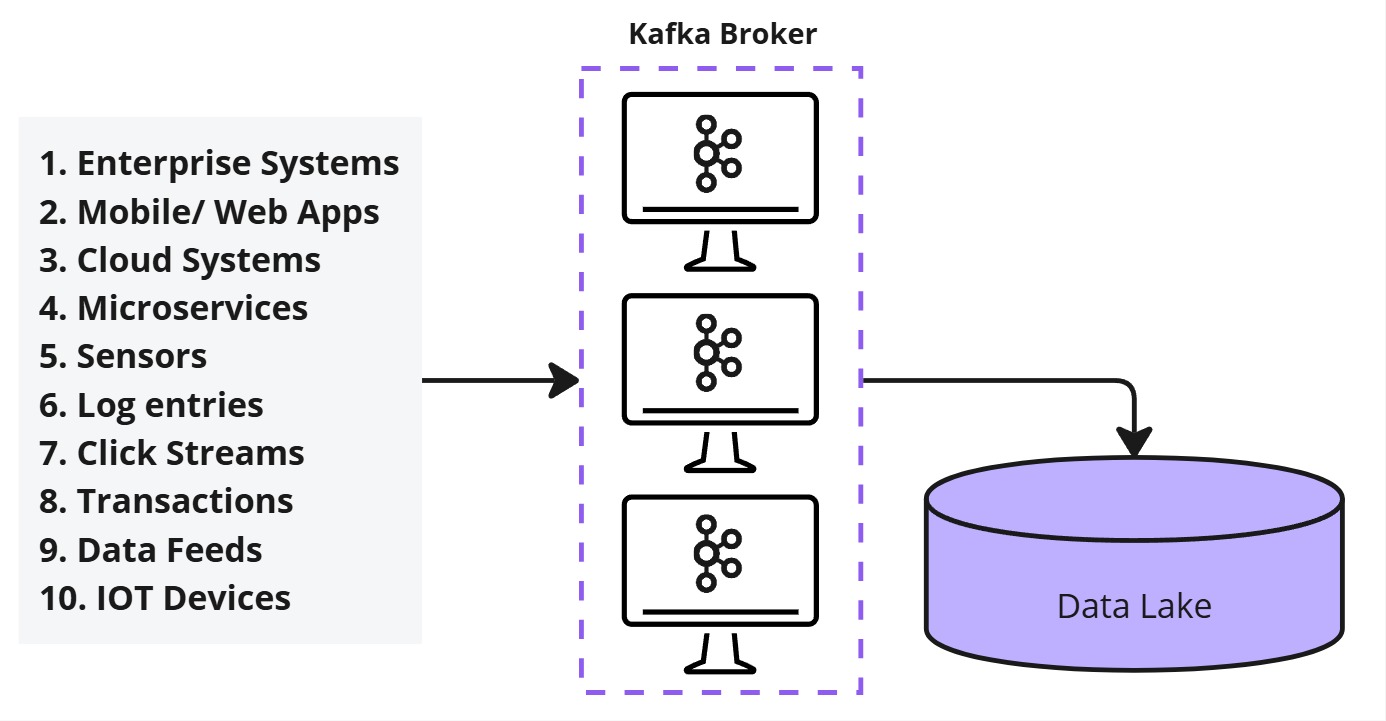
For integrating real-time data into a Data Warehouse or Data Lake:
- Collect data from multiple source systems into a Kafka cluster.
- Sink data into a Data Lake for further processing.
- Process the data using batch or stream processing frameworks.
- Query real-time summaries using KSQL.
Role of KSQL:
- Allows using Kafka as a real-time data warehouse.
- Supports SQL-like queries for real-time analytics.
- Generates live summaries that update every second/millisecond.
Final Step:
- Kafka primarily moves data into the Lakehouse.
- Spark Structured Streaming handles the rest of the real-time processing within the lakehouse environment.
Kafka in the Enterprise Ecosystem
Kafka serves as the central hub in a real-time data ecosystem. Data flows seamlessly from producers to consumers with minimal latency, often in milliseconds. Its decoupled architecture ensures flexibility and producers don’t need to know who will consume the data, and consumers can be added or modified without disrupting the system. By adopting Kafka, organizations can achieve scalable, real-time data integration, ensuring critical business events are processed instantly. In the next sections, we’ll explore Kafka’s core concepts, Kafka Connect, Kafka Streams, and when to use each component.
Kafka Components
Apache Kafka is built on a set of core components that enable efficient, distributed, and real-time data streaming.
1. Producer – The Data Sender
A producer is an application that sends data (messages) to Kafka. Each message is simply an array of bytes, and the producer is responsible for formatting and sending them to the correct Kafka topic.
Examples of Producers:
- Sending a data file to Kafka: Each line of the file can be sent as a separate message.
- Streaming database records: Each row of a database table can be converted into a Kafka message.
- Query results as messages: A producer application can execute a query, fetch the results, and stream each row as a message.
Kafka provides out-of-the-box producers through Kafka Connect, which simplifies integration with external data sources without writing custom producer applications.
2. Consumer – The Data Receiver
A consumer is an application that reads data from Kafka. Since Kafka follows a Publish-Subscribe (Pub/Sub) model, producers don’t send messages directly to consumers. Instead, consumers fetch messages from Kafka topics whenever they need them.
How Consumers Work:
- A consumer requests data from a Kafka topic.
- The Kafka broker sends messages to the consumer in the order they were produced.
- The consumer processes the data and requests more messages in a loop.
Use Case Example:
If a producer sends a data file to Kafka, a consumer application can be built to retrieve and process the file line by line. Consumers can then perform actions like aggregating data, generating alerts, or storing results in a database.
3. Kafka Broker – The Central Message Hub
A broker is the Kafka server that acts as an intermediary between producers and consumers. Kafka brokers store messages, maintain partitions, and handle client requests efficiently.
4. Kafka Cluster – A Group of Brokers
Kafka is designed as a distributed system, meaning it can run on multiple machines. A Kafka cluster consists of multiple brokers working together to improve performance, availability, and scalability.
5. Topic – The Logical Data Stream
A topic is a named stream of messages in Kafka. It functions like a database table, where producers write messages, and consumers read them.
Key Characteristics of Topics:
- Topics are created before data can be published.
- Each topic can have multiple producers and consumers.
- Kafka retains messages for a configurable duration, allowing consumers to process them at different times.
6. Topic Partitions – Distributed Storage for Scalability
Since Kafka stores large volumes of data, a single machine may not have enough capacity to handle all messages in a topic. To solve this, Kafka divides topics into partitions and distributes them across multiple brokers in the cluster.
Benefits of Partitions:
- Scalability: Spreads data across multiple brokers, allowing Kafka to handle massive data loads.
- Parallelism: Consumers can process partitions in parallel, improving performance.
- Fault Tolerance: If one broker fails, another can take over its partitions.
Design Consideration:
Kafka does not automatically determine the number of partitions. Instead, architects must decide based on expected data volume. Once set, a partition cannot be further divided, so careful estimation is necessary.
7. Partition Offset – Tracking Message Order
Each message in a partition is assigned a unique, immutable offset ID when it arrives.
How Offsets Work:
- The first message in a partition gets offset 0, the next offset 1, and so on.
- Offsets are local to a partition, meaning there is no global ordering across partitions in a topic.
- To retrieve a specific message, you need: Topic Name, Partition Number, and Offset Number.
Example of Partition Offsets in a Topic with 3 Partitions:
| Partition | Message | Offset |
|---|---|---|
| Partition 0 | “Event A” | 0 |
| Partition 0 | “Event B” | 1 |
| Partition 1 | “Event C” | 0 |
| Partition 2 | “Event D” | 0 |
| Partition 2 | “Event E” | 1 |
Since each partition maintains its own sequence, there is no global ordering across partitions.
What is a Consumer Group?
It is a group of consumers. Multiple consumers can form a group to share the workload.
In a scenario where we want to bring all data from multiple sources to a data center, the first thing that we want is a producer at every source location.
These producers are going to send the data as messages to the Kafka topic. The next thing that you want to do is to create the consumer.
The consumer is going to read the data from the Kafka topic and write it to the data center. All we want to do is to bring the data to the data center as quickly as we can.
The Problem: Scale
You have hundreds or maybe thousands of producers pushing data into a single topic.
How do we handle the volume and velocity at the broker? We can create a large Kafka cluster and partition the topic.
So the topic is partitioned and distributed across the cluster. Now every broker has got a topic partition, so it can take the data from a producer and store it in the partition.
On the data source side, you have hundreds of producers and a bunch of brokers to share the workload.
Why Partitioning?
Partitioning is not only a solution to increase storage capacity but also a method to distribute the workload. Kafka topic partitions are the core idea that makes Kafka a distributed and scalable system. Partitions are the most valuable concept to understand how Kafka behaves as a distributed and scalable platform.
######## Scaling the Consumer Side How is it going to handle so much incoming data alone? This is where the consumer group comes in.
We can create a consumer group, start multiple copies of the consumer application in the same group, and let them divide the workload.
How is the Work Divided?
Let’s say we have 500 topic partitions and start 100 consumers in a group.
- Each consumer will take five partitions, and together they will process all 500 partitions.
- We monitor the load and check if a single consumer can handle five partitions.
- If not, we add more consumers to the group.
- We can scale up to 500 consumers, so each consumer handles just one partition.
Key Takeaways
- Topic partitions enable scalability.
- The number of maximum parallel consumers is limited by the number of partitions in the topic.
- Kafka does not allow more than one consumer to read from the same partition simultaneously to avoid duplicate processing.

Lais Ziegler
Dev in training... 👋