Real-Time Stream Processing with Kafka Streams
- 6 minsWhat is Real-Time Stream Processing?
In today’s world, data is constantly being generated from multiple sources. These data streams are:
- Unbounded – No definite starting or ending point.
- Often infinite – Ever-growing without stopping.
- Structured in small packets – Typically measured in kilobytes.
Examples of Data Streams
Real-time data streams come from various sources, including:
- Sensor Data – Transportation vehicles, industrial equipment, healthcare devices, and wearables.
- Log Entries – Generated by mobile apps, web applications, and infrastructure components.
- Click Streams – Tracked in e-commerce, news websites, video streaming platforms, and online gaming.
- Transactions – Found in stock markets, credit card systems, ATMs, eCommerce orders, and logistics.
- Data Feeds – Includes social media activity, traffic updates, security alerts, and threat detection systems.
Processing these continuous streams of data is a challenge. There are three common approaches:
- Querying – Storing data in a system and querying it for specific answers (request-response model).
- Batch Processing – Running scheduled jobs to process large amounts of stored data at regular intervals.
- Stream Processing – Asking a question once and continuously receiving updated answers as new data arrives.
While databases and batch processing systems can be used for stream processing, they often become too complex when dealing with real-time data. This is where Kafka Streams comes in.
What is Kafka Streams?
Kafka Streams is a Java/Scala library that enables real-time data processing directly from Kafka topics. Unlike traditional stream processing systems, Kafka Streams offers several key advantages:
- Embedded in Microservices – Runs within existing applications without requiring a separate cluster.
- Scalable and Fault-Tolerant – Handles distributed processing with built-in fault tolerance.
- Flexible Processing – Allows working with both streams and tables, joining them, and computing aggregates.
- Efficient Local State Stores – Manages state efficiently with fault tolerance.
- Time Handling – Supports event time, processing time, late data handling, and exactly-once processing.
- Interactive Queries – Provides a request/response interface for querying processed streams.
- Easy Deployment – Can be deployed in containers and managed with Kubernetes.
How Kafka Streams Works
Kafka Streams continuously reads data from Kafka topics and processes it in real-time.
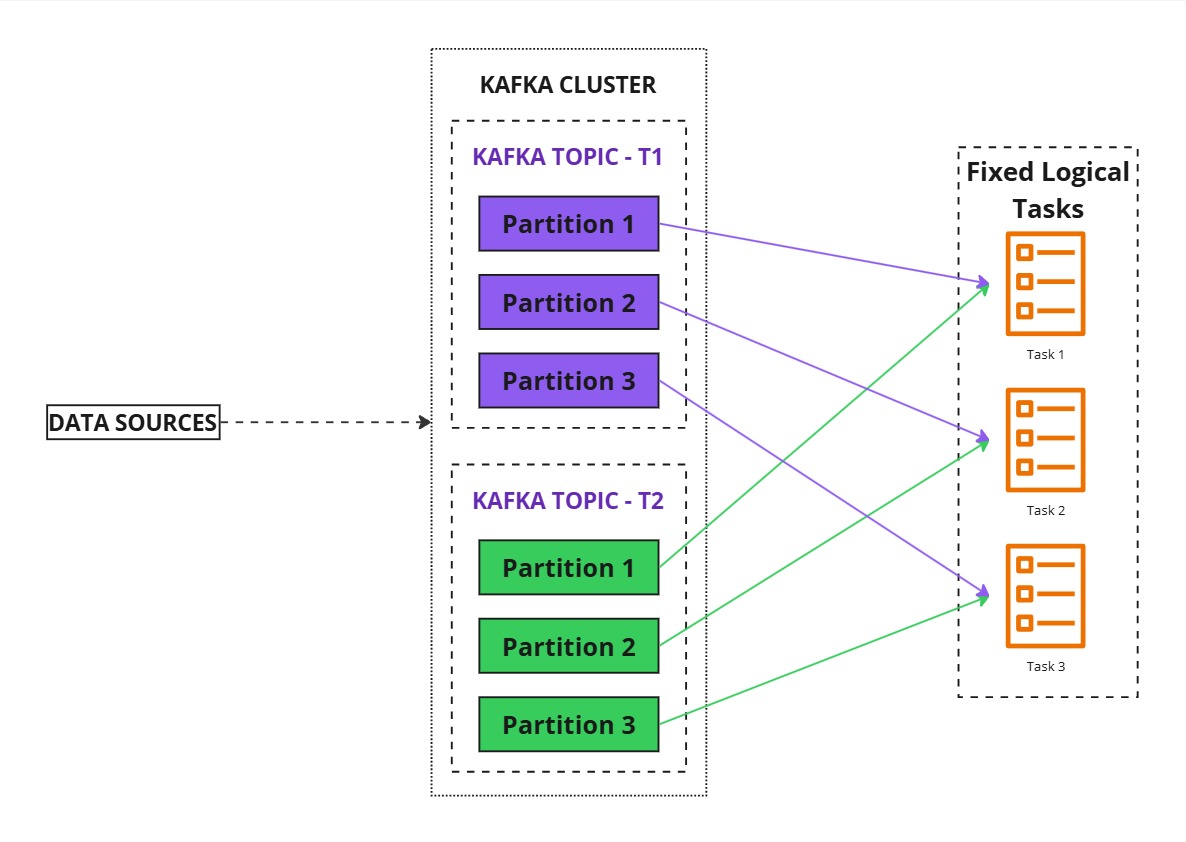
Kafka Streams Architecture Example
- Consuming Data
- A Kafka Streams application reads data from two Kafka topics (T1 and T2), each with three partitions.
- Kafka Streams internally creates three logical tasks (one per partition) for parallel processing.
- These tasks are then assigned to application threads.
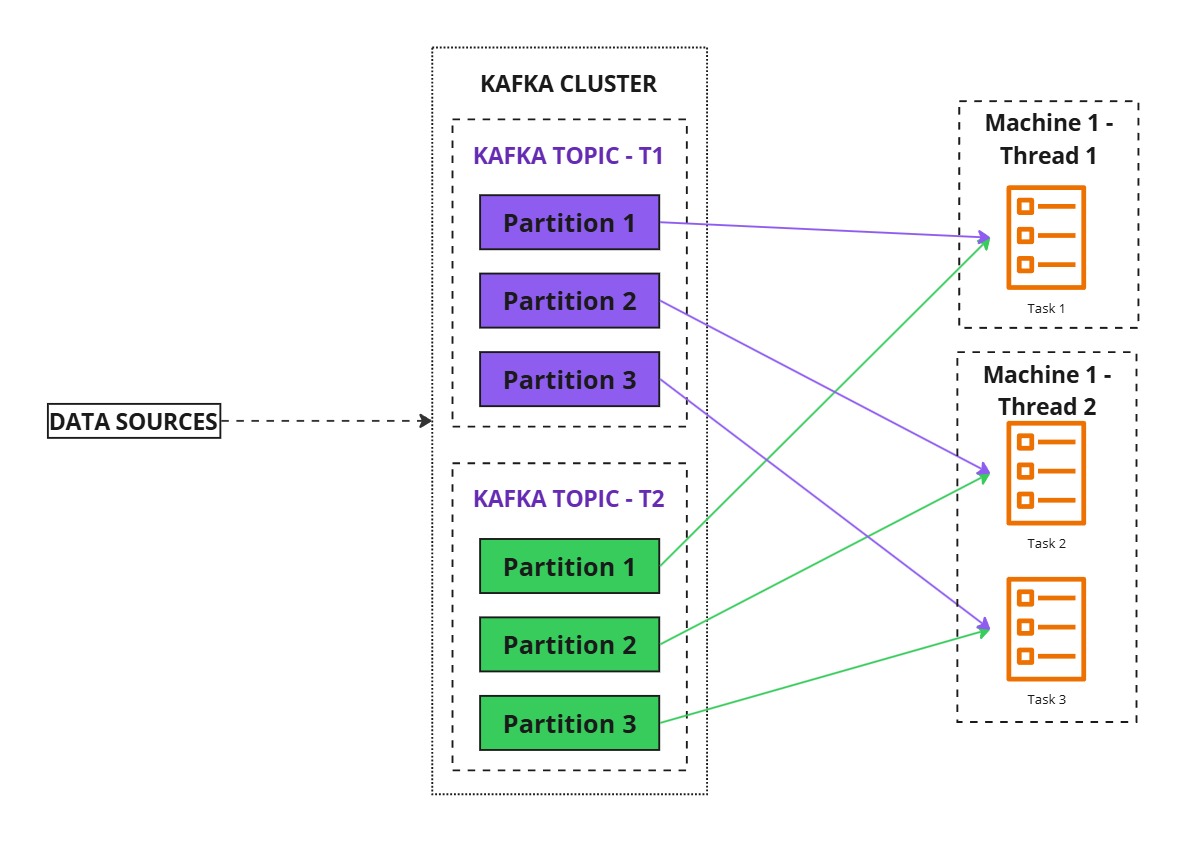
- Scaling Up
- If the application runs on a single machine with two threads, Kafka Streams assigns tasks accordingly.
- Uneven task distribution can occur if threads are not enough.
- Increasing the number of threads allows better parallelism and workload sharing.
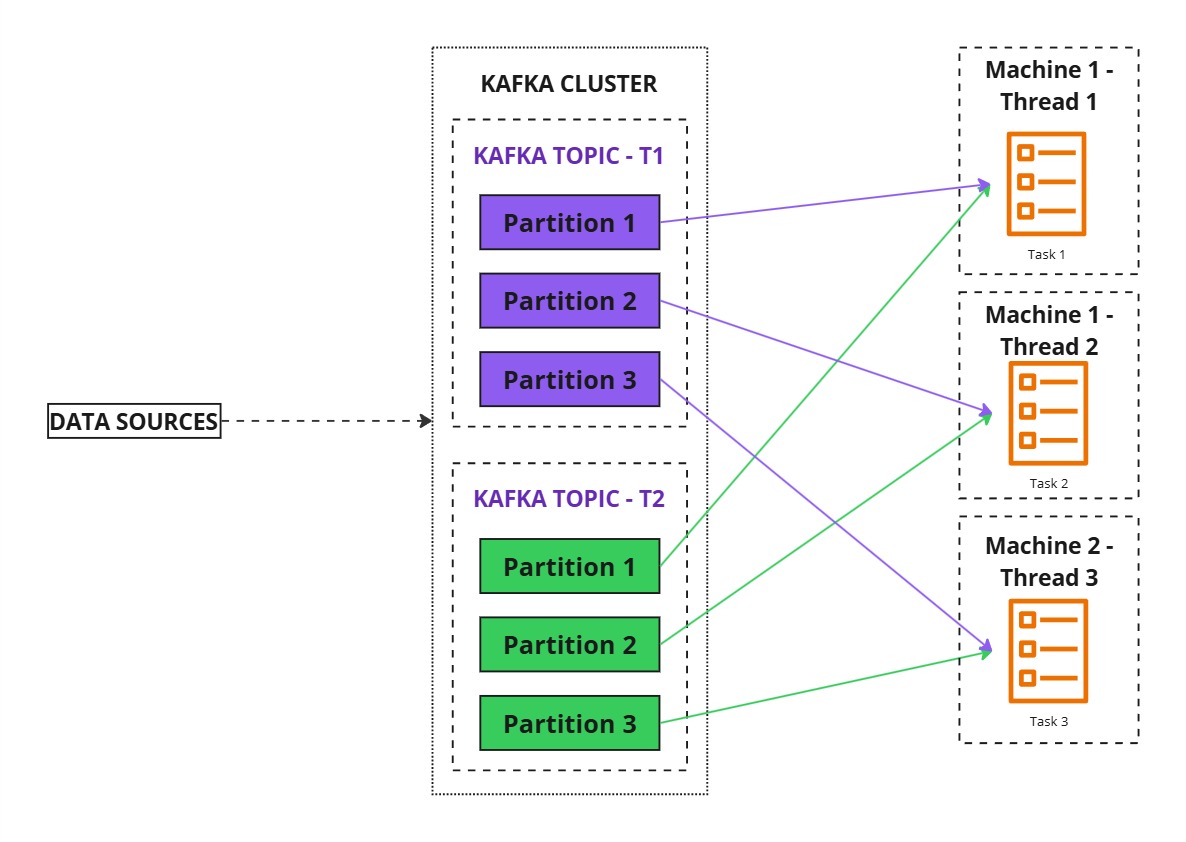
- Scaling Out
- Deploying another instance of the application on a different machine creates a new thread (T3), automatically redistributing tasks.
- This process, called task reassignment, ensures workload balancing across multiple instances.
- If the number of instances exceeds the available partitions, extra instances remain idle.
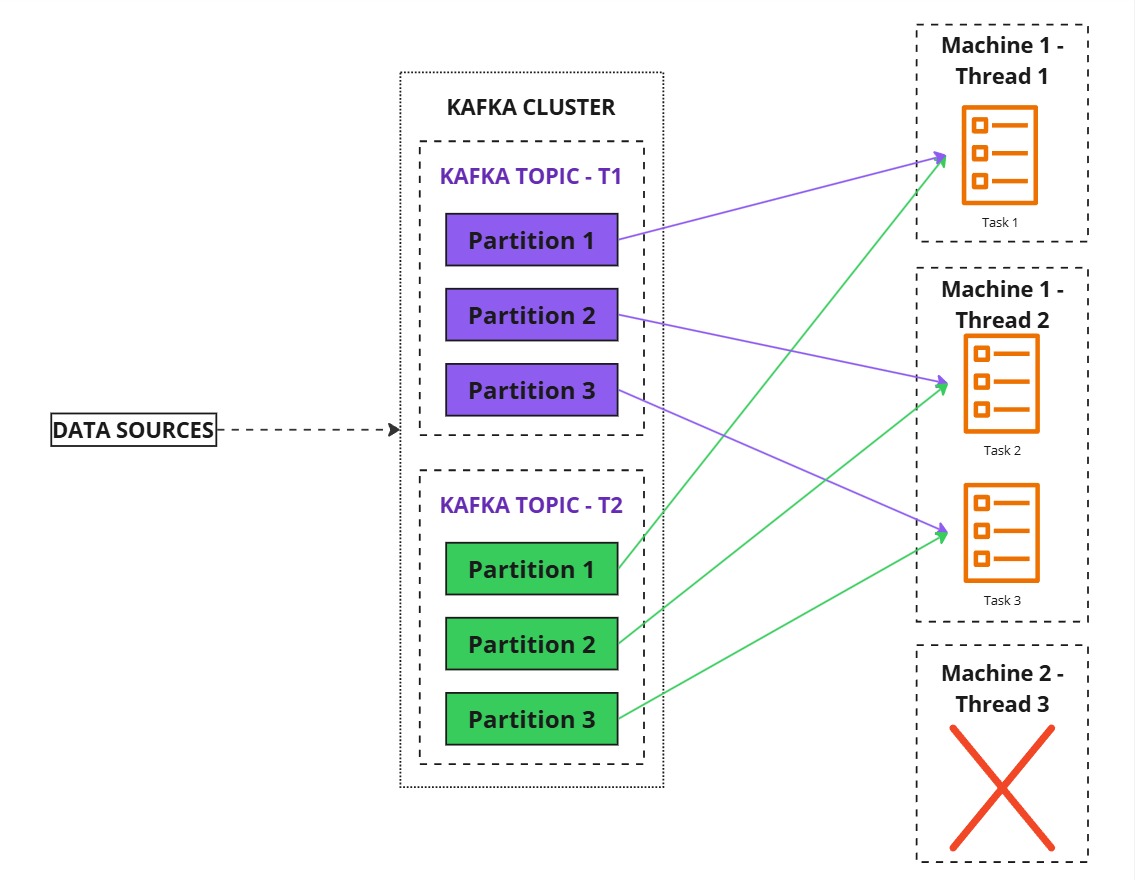
- Fault Tolerance
- If an instance crashes, Kafka Streams automatically reassigns its tasks to the remaining running instances.
- This ensures seamless failure handling without user intervention.
Why Use Kafka Streams?
Kafka Streams provides a powerful yet lightweight solution for real-time stream processing. It simplifies complex event-driven processing with built-in scalability, fault tolerance, and dynamic workload balancing. Whether you’re working with sensor data, clickstreams, transactions, or log files, Kafka Streams ensures efficient real-time analytics with minimal operational overhead.
KSQL – SQL for Kafka Streams
KSQL provides a SQL-like interface for Kafka Streams, making stream processing accessible without requiring Java or Scala coding.
Why Use KSQL?
- SQL-based stream processing – No need for programming.
- Scalable & fault-tolerant – Runs in a distributed environment.
- Interactive & Headless Modes – Interactive for development, headless for production.
How KSQL Works
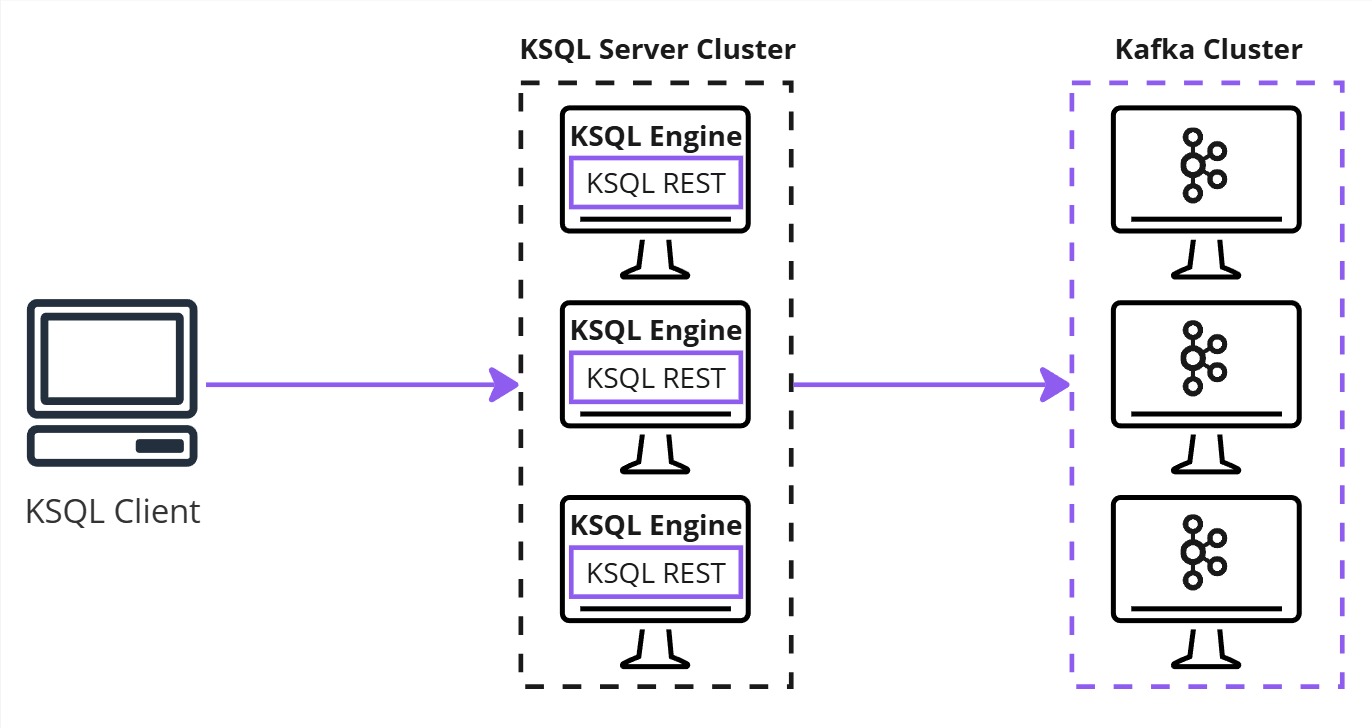
KSQL has three key components:
- KSQL Engine – Parses and executes KSQL queries.
- REST Interface – Facilitates communication with clients.
- KSQL Clients – CLI or UI for writing and running queries.
KSQL allows you to use your Kafka topic as a table and fire SQL-like queries over those topics. With KSQL you can:
1. Group and Aggregate on Kafka Topics
Count the number of times each song is played:
CREATE TABLE song_plays AS
SELECT song_id, COUNT(*) AS play_count
FROM song_stream
GROUP BY song_id;
2. Group and Aggregate Over a Time Window
Track popular songs over the last hour:
CREATE TABLE trending_songs AS
SELECT song_id, COUNT(*) AS play_count
FROM song_stream
WINDOW TUMBLING (SIZE 1 HOUR)
GROUP BY song_id;
3. Apply Filters
Find trending songs in a specific region:
CREATE TABLE regional_trending_songs AS
SELECT song_id, COUNT(*) AS play_count
FROM song_stream
WINDOW TUMBLING (SIZE 1 HOUR)
WHERE region = 'North America'
GROUP BY song_id;
4. Join Two Topics
Enhance the dataset by joining song metadata:
CREATE TABLE song_details AS
SELECT s.song_id, s.play_count, m.artist_name, m.genre
FROM trending_songs s
JOIN song_metadata m
ON s.song_id = m.song_id;
5. Sink the Result into Another Topic
Store the results in a Kafka topic for further processing:
CREATE STREAM popular_songs WITH (KAFKA_TOPIC='popular_songs_topic') AS
SELECT * FROM song_details;
With KSQL, you can transform Kafka into a real-time data warehouse. The future might even bring JDBC/ODBC connectors for visualization tools like Tableau and QlikView, making real-time analytics even more accessible.
Kafka Streams and KSQL make real-time stream processing easier and more efficient. Whether you’re developing a microservice, aggregating real-time metrics, or analyzing data streams, Kafka Streams and KSQL offer powerful tools to handle your data efficiently.

Lais Ziegler
Dev in training... 👋