RabbitMQ Overview
- 12 minsMessaging is a form of communication. It is a mechanism for loosely coupled integration between software components, applications, or even multiple systems. It enables structured communication, similar to SOAP, where messages contain headers and bodies, acting as envelopes that encapsulate information. When a system receives a message, it processes the content and takes appropriate action.
The Role of Messaging in Software Systems
Messaging is a fundamental concept in computing, from operating system kernels to CPU memory management. Every component in a system must communicate in some way, and there are multiple ways to achieve this, including method calls, remote procedure calls (RPCs) and HTTP clients and servers.
These approaches, however, are synchronous, meaning a request triggers an immediate response. While effective, they create tight coupling between components, limiting flexibility and scalability.
Why Do We Need Messaging Protocols?
Although we already have functions, methods, and other communication mechanisms, they are not always the best fit for scalable and decoupled architectures. Messaging protocols address these challenges by enabling:
- Asynchronous processing – Messages are queued and processed one by one, preventing system overload.
- Loose coupling – Components communicate without direct dependencies, improving scalability and flexibility.
- Encapsulation of information – Messages can carry any type of data within a structured format.
Additionally, messaging protocols offer advanced mechanisms to control message flow through the system, such as Queues, Topics, Channels and Exchanges.
Messaging Protocols
The choice of messaging protocol determines how these structures operate and integrate within a system. They define the ways messages are transferred across networks, enabling communication between devices, applications, and systems. These protocols are used everywhere, from simple client-server communication to complex distributed systems.
The three most commonly used messaging protocols are STOMP, MQTT and AMQP.
STOMP (Simple Text Oriented Messaging Protocol)
STOMP is a lightweight protocol designed for exchanging simple text-based messages.
Key Features:
- Provides an interoperable format, allowing communication between clients and STOMP message brokers across different languages and platforms.
- Designed similarly to HTTP, making it easy to understand and implement.
- Does not have built-in concepts like queues and topics but allows receivers to implement their own messaging structures.
- Uses a SEND semantic with a destination string to specify where the message should be delivered.
MQTT (Message Queue Telemetry Transport)
MQTT is a protocol designed for efficient, lightweight communication, particularly in Machine-to-Machine (M2M) and Internet of Things (IoT) applications.
Key Features:
- Based on a publish-subscribe model, where messages are sent to a destination and subscribed clients automatically receive them.
- Developed for resource-constrained devices and low-bandwidth, high-latency networks (e.g., satellite links, dial-up connections).
- Uses compact binary packets, meaning minimal metadata and compressed headers for efficient transmission.
- Supports thousands of concurrent device connections, making it ideal for IoT and mobile applications.
- Backed by industry giants and highly standardized for reliability.
AMQP (Advanced Message Queuing Protocol)
AMQP is a reliable and interoperable messaging protocol that facilitates communication across diverse platforms, applications, and services. It allows seamless integration between different language applications, enabling them to communicate without relying on a single system, app, or language.
Key Features:
- Cross-platform compatibility: All AMQP clients work with all AMQP servers, ensuring wide interoperability.
- Highly standardized: AMQP provides a robust, well-defined specification, making it suitable for varied use cases.
- Comprehensive messaging capabilities:
- Queuing
- Topic-based publish-subscribe messaging
- Flexible routing
- Transactions
- Security
- Legacy support: AMQP can retrofit older message brokers, removing proprietary protocols from networks.
- Cloud-friendly: It’s a platform-agnostic protocol that works seamlessly in cloud environments. Simply deploy an AMQP broker in the cloud to start publishing and subscribing to messages.
- Reliability: With AMQP, you can define your messaging exchanges as transactions, and implement failover and retry mechanisms, ensuring more reliable communication.
Use Cases:
- Real-time feeds: Ideal for applications that require constantly updating information.
- Encrypted, assured transactions: Highly secure and reliable messaging for sensitive data.
- Offline message delivery: Messages can be stored and delivered once the destination is online.
- Large message handling: Supports sending large messages while receiving status updates over the same connection.
AMQP simplifies the technical complexity of connecting diverse systems and applications, allowing you to focus on higher-value tasks, such as responding to real-time information and optimizing workflows.
RabbitMQ
RabbitMQ is a powerful, open-source message broker, often referred to as Message-Oriented Middleware. It is the most popular implementation of the AMQP protocol and provides a robust and flexible messaging platform designed to interoperate with other messaging systems. This means you can easily integrate RabbitMQ with other AMQP providers.
Key Features:
- Built in Erlang: Developed using Erlang, RabbitMQ is designed for high concurrency and reliability.
- Clustering for Fault Tolerance and Scalability: RabbitMQ supports clustering, enabling multiple brokers to work together for high availability and scalable message processing.
- If a single broker isn’t sufficient, you can cluster different RabbitMQ brokers to create a highly scalable, fault-tolerant system.
- Efficient Connection Handling: RabbitMQ allows multiple connection channels within a single TCP connection, reducing the overhead of establishing multiple TCP connections to the broker.
Common Usage:
- AMQP-based Communication: RabbitMQ uses AMQP to define exchanges, queues, and bindings between them, which is considered almost a best practice for message processing.
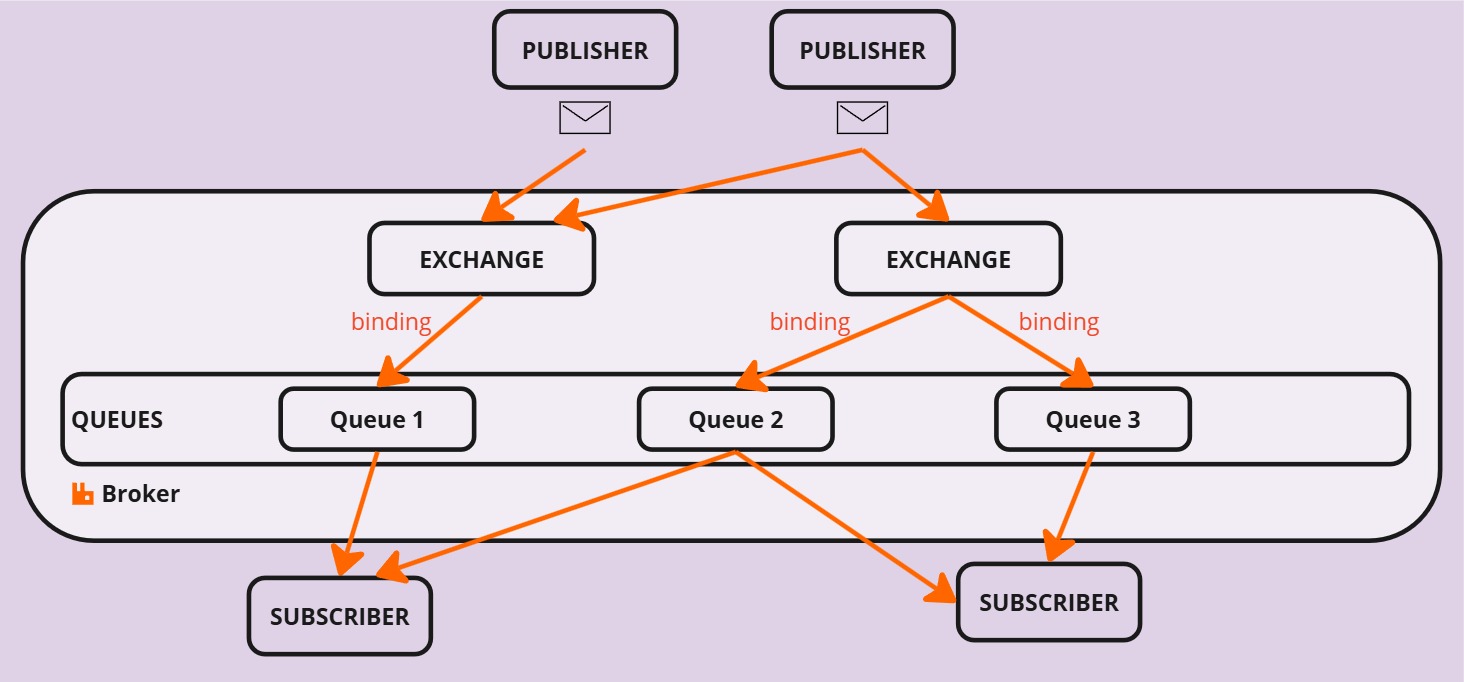
In RabbitMQ, the message flow starts with publishers and ends with subscribers.
Publishers:
- Publishing to Exchanges: Publishers send messages to exchanges, which are responsible for routing the messages to the appropriate queues. Messages can be published to a default exchange or any custom exchange defined by the publisher.
Subscribers:
- Listening for Messages: Subscribers listen for messages from queues. They can filter messages based on specific topics, keywords, or even receive all messages.
- Queue Bindings: Exchanges deliver messages to queues based on bindings. A binding is a rule that defines how an exchange is connected to a queue. You can bind an exchange to multiple queues, allowing messages to be delivered to multiple queues and subsequently received by multiple subscribers.
Key Concepts:
- Exchanges are the starting point for publishers, where they send their messages.
- Queues are the focal point for subscribers, who receive messages from these queues.
- Bindings define the connection between exchanges and queues, ensuring messages flow smoothly from publishers to subscribers.
Actors of Messaging with RabbitMQ: Exchanges, Queues, Topics, and Bindings
In RabbitMQ, the messaging flow involves several actors working together to ensure that messages are routed and delivered effectively.
Producer and Consumer Lifecycle:
- Producer: The producer generates messages and sends them to an exchange.
- Consumer: The consumer waits for and processes messages from a queue.
- Message Lifecycle: The message follows an infinite lifecycle: once published, it moves from the producer to the exchange, then is routed to a queue for the consumer to consume.
Exchanges:
- Definition: An exchange is where messages are sent initially in the AMQP model. It routes messages to one or more queues based on routing rules.
- Routing Algorithm: RabbitMQ uses built-in routing algorithms to decide how messages should be routed from exchanges to queues. These algorithms depend on the exchange type and defined bindings.
- Functionality: You send a message to an exchange, and the exchange determines which queue(s) should receive it.
Exchange Types:
RabbitMQ supports four main exchange types:
- Direct Exchange (
amq.direct):- Delivers messages to the queue that is directly bound to it.
- Default for simple message routing.
- Fanout Exchange (
amq.fanout):- Distributes messages to all queues bound to it.
- Ideal for broadcasting messages to multiple consumers.
- Topic Exchange (
amq.topic):- Delivers messages based on matching the routing key with a specific topic pattern.
- Useful when you need messages to be sent to specific queues based on topics (e.g., “app.logs.error”).
- Header Exchange (
amq.match):- Routes messages based on matching message headers.
- Allows more flexible routing using header attributes rather than just the routing key.
Queues:
- Definition: Queues are the final destination for messages before they are consumed by a subscriber.
- Routing: Messages are routed from exchanges to queues based on the exchange type and binding configurations.
- Properties:
- Name: The identifier for the queue.
- Durable: Whether the queue persists across broker restarts.
- Exclusive: The queue is exclusive to the connection and deleted when the connection closes.
- Auto-Delete: The queue is automatically deleted when the last consumer unsubscribes.
Topics:
- Definition: Topics are part of the message’s routing key, used for grouping and filtering messages.
- Example: A topic could be defined as
app.logs.errorto indicate messages related to error logs. - Usage: Topics allow for targeted message delivery to interested consumers.
Bindings:
- Definition: Bindings are the configurations that connect exchanges to queues, determining how messages are routed.
- Routing Key: The routing key acts as a filter to direct messages to the appropriate queues.
- Handling Unrouted Messages: If a message cannot be routed to any queue (due to missing bindings), it may either be dropped or returned to the publisher, depending on the publisher’s settings.
- Purpose: Bindings ensure that messages sent to an exchange are delivered to the appropriate queue. They specify the connection rules between exchanges and queues.
Comparing RabbitMQ vs Kafka
While both RabbitMQ and Kafka are widely used message brokers, they cater to different messaging patterns and system requirements. Let’s compare them based on their features and use cases:
1. Message Delivery Guarantees:
- RabbitMQ: Guarantees at least once delivery, ensuring that messages are routed to queues and consumers. However, in some cases, messages may be delivered multiple times if retries occur.
- Kafka: Guarantees at least once delivery by default, with an option for exactly once delivery when configured. Kafka is designed for high-throughput and can store messages for a longer time, making it suitable for streaming.
2. Message Ordering:
- RabbitMQ: Does not guarantee strict ordering of messages unless specifically configured (e.g., single consumer per queue).
- Kafka: Guarantees strong message ordering within a partition, making it ideal for use cases that require message sequence preservation.
3. Performance and Throughput:
- RabbitMQ: Well-suited for low-latency, high-priority message delivery and supports complex routing and message patterns.
- Kafka: Optimized for high-throughput, large-scale data streaming. It can handle millions of messages per second, making it a better fit for big data use cases and real-time data pipelines.
4. Use Case Suitability:
- RabbitMQ: Ideal for traditional messaging use cases like task queues, RPC, and when you need to support multiple consumer patterns (e.g., pub/sub, work queues).
- Kafka: Best for event sourcing, log aggregation, and real-time analytics due to its high throughput and persistence capabilities.
5. Message Retention:
- RabbitMQ: Messages are typically removed after consumption or based on TTL (time-to-live) configuration. It’s a more transient system.
- Kafka: Messages are retained for a configured time window, which allows consumers to reprocess messages even after they’ve been delivered. Kafka’s logs act as a durable storage for streams of data.
6. Scalability:
- RabbitMQ: Scales horizontally with clustering, but the process can become complex and challenging at very large scale.
- Kafka: Natively scalable, designed to scale horizontally with partitioning, replication, and distributed architectures. It’s better suited for handling large-scale, distributed systems.
7. Persistence and Fault Tolerance:
- RabbitMQ: Supports durable queues and persistent messages, ensuring that messages are not lost during a broker restart, but its persistence model is less robust compared to Kafka.
- Kafka: Highly fault-tolerant and designed for long-term message storage. It uses replication to ensure data durability and recovery in the case of broker failures.
8. Consumer Model:
- RabbitMQ: Employs a push model, where messages are pushed to consumers as they become available. It supports both queue-based and topic-based delivery.
- Kafka: Uses a pull model, where consumers pull messages from Kafka topics at their own pace. This makes Kafka well-suited for systems that need to process streams of data at varying rates.
When to Use RabbitMQ:
- When you need complex message routing (e.g., topic-based, direct, fanout).
- For task queueing, where message order isn’t always critical.
- When low-latency delivery and fine-grained acknowledgement control are required.
- For enterprise integration where various services with different protocols need to communicate.
When to Use Kafka:
- When you require high-throughput and can process large amounts of messages.
- For event-driven architectures, such as event sourcing or log aggregation.
- When message persistence and the ability to replay historical events are essential.
- For distributed data pipelines that process and aggregate real-time data across multiple systems.
Key Differences
| Feature | RabbitMQ | Kafka |
|---|---|---|
| Protocol | AMQP (Advanced Message Queuing Protocol) | Kafka’s own protocol |
| Message Delivery | At least once delivery | At least once, exactly once (with configuration) |
| Message Ordering | No strict ordering by default | Guarantees ordering within partitions |
| Performance | Low latency, moderate throughput | High throughput, suitable for large data volumes |
| Message Retention | Typically removed after consumption or TTL | Retains messages for configurable period |
| Consumer Model | Push-based (messages pushed to consumers) | Pull-based (consumers pull from topics) |
| Message Persistence | Limited, typically for short periods | Long-term persistence, ideal for streaming |
| Fault Tolerance | Supports clustering but more complex | Built-in replication and fault tolerance |
| Scalability | Scalable with clustering, complex at scale | Easily scalable horizontally with partitions |
| Use Cases | Task queues, RPC, complex routing | Event sourcing, real-time data processing, log aggregation |

Lais Ziegler
Dev in training... 👋